An Analogy for Understanding Mixture of Expert Models
TL;DR: Experts are Doctors, Routers are GPs
Motivation
Foundation models aim to solve a wide range of tasks. In the days of yore, we would build a supervised model for every individual use case; foundation models promise a single unified solution.
There are challenges with this however. When two tasks need different skills, trying to learn both can make you learn neither as well as if you had focused on one1. Storing information for many tasks can also be a challenge, even for large models.
Moreover we might wonder if it make sense to use the same parameters for computing the answer to a logic puzzle and for finding the perfect adjective to describe the love interest in a romance fanfic.
We would like our models to have modular functions. We could then select and even combine abilities when needed.
MoEs For Scale
Scaling up models offers various advantages. There are three main quantities to
scale: the number of model parameters, the amount of data and the amount of
compute applied at train time. With regular transformers, to scale up the
number of parameters, we must likewise scale the amount of compute applied.
Intuitively more parameters mean more
knowledge, and more compute represents additionalintelligence2.
There are some use cases where having more knowledge can be traded off with being more cognitively able. For example, you may choose to memorise rather than re-derive the laws of physics to use them in a specific problem. Similarly we can trade off the opposite way as well - if you know you’ll have access to a textbook or Wikipedia then you might not want to memorise certain historical facts. All you need to know is when and how to look up the facts you need.
So, dependent on whether we need more knowledge or more cognitive ability, we also want to scale parameters and compute separately3.
Sparse Mixture of Experts Models
In a vanilla transformer, each Transformer Block contains an attention layer for
communication between tokens and an MLP layer for computation within
tokens. The MLP layer contains most of the parameters of a large transformer and
transforms the individual tokens.
In Sparse Mixture of Experts (MoEs), we
swap out the MLP layers of the vanilla transformer for an Expert Layer. The
Expert Layer is made up of multiple MLPs called “Experts”. For each input we
select one expert to send that input to. In this way, each token has different
parameters applied to it. A dynamic routing mechanism decides how to map tokens
to Experts4.
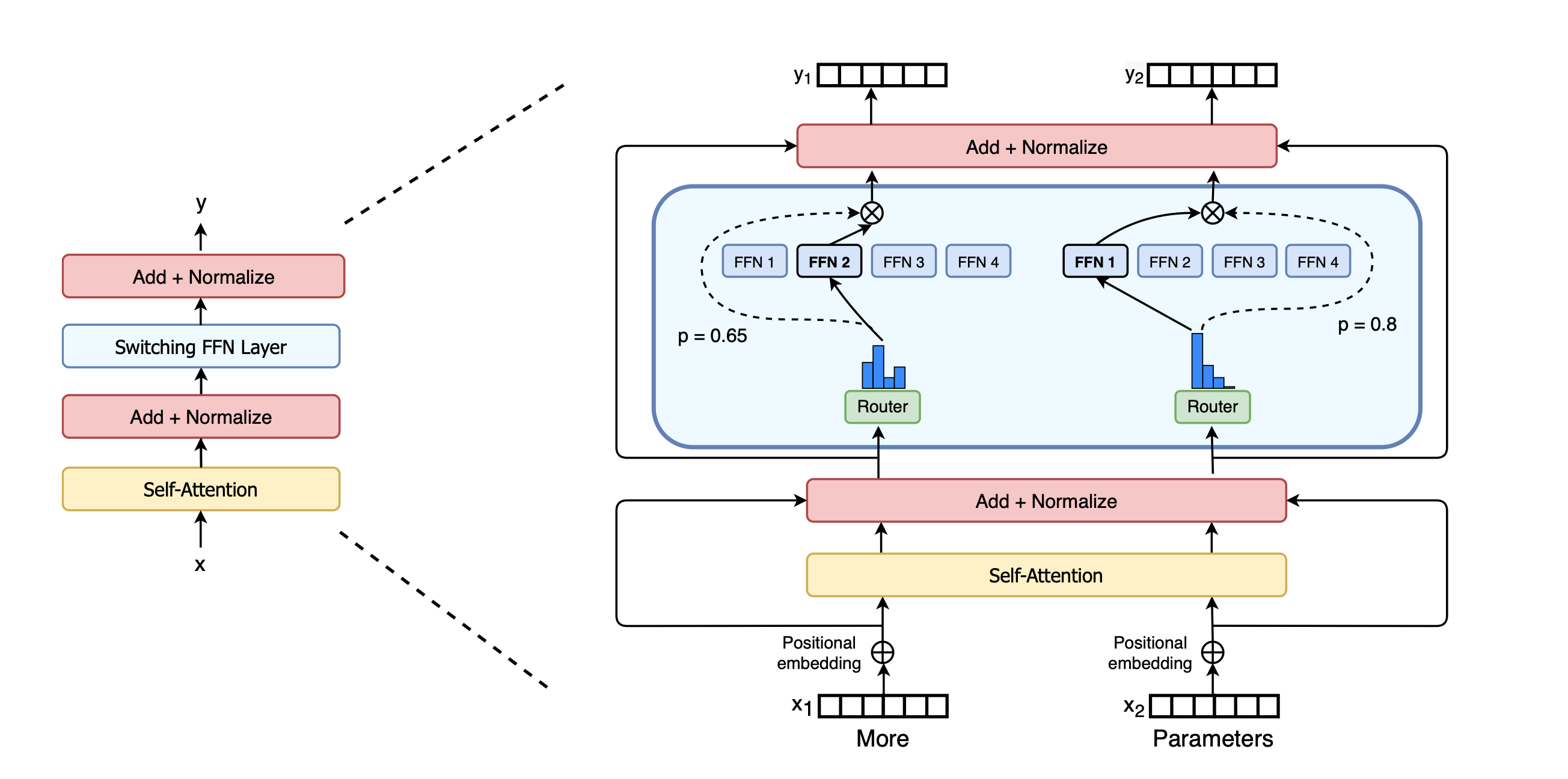
Sparse MoEs solve the problems we noted earlier:
- MoEs allow their internal “Experts” to specialise in certain domains rather than having to be all things to all tokens 5 6.
- And with MoEs, we are able to increase the number of parameters of models without increasing how much training compute or inference time latency. This decouples parameter scaling from compute scaling (i.e. we decouple knowledge from intelligence)
The Analogy
Imagine you’re feeling fatigued and you have no idea what’s causing this. Suppose the problem is with your eyes but you don’t know this yet. Since your friend is a cardiologist (doctor specialising in the heart), you ask them for advice, which they freely give. You might ask yourself if you should follow their advice blindly or if you should:
Approach 1: Get a second opinion from another cardiologist.

Averaging over multiple doctors who were trained in the same way increases robustness by reducing variance (maybe the first doctor was tired that day or something). But it doesn’t help with bias 7 - all the cardiologists are likely to be wrong in the same way, if they are wrong at all.
Approach 2: Go to a generalist doctor that has no specialism.
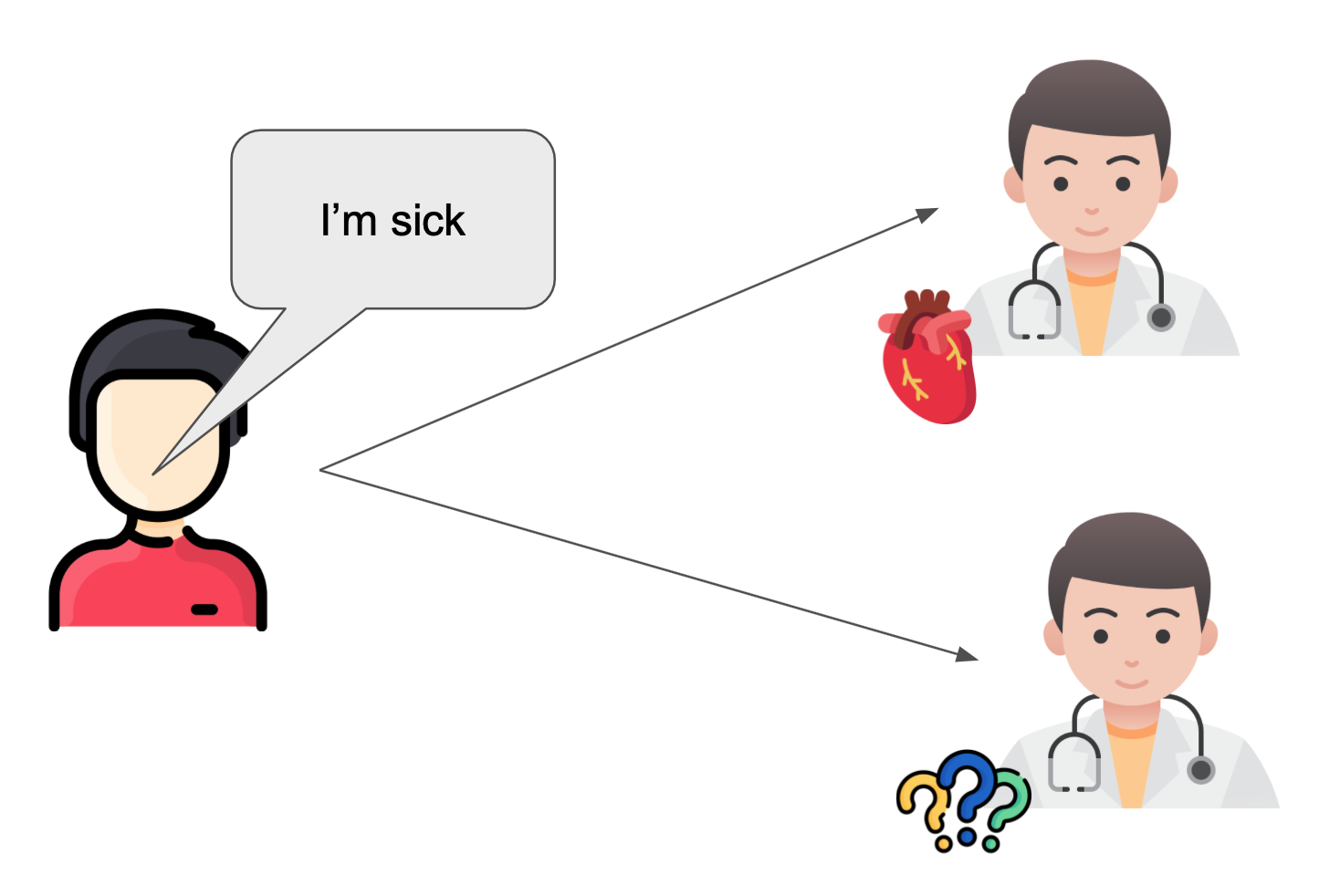
It’s not clear whether this is better than asking another cardiologist. Sure they might have different knowledge to the cardiologist which might be useful if your problem isn’t about the heart. But there’s an awful lot of medical knowledge out there and we can’t reasonably expect this one generalist to know everything about all of them. They probably have cursory knowledge at best. We need someone who specialises in the area that we’re struggling with. Problem is we don’t know which area of specialism we need!
Approach 3: Ask multiple doctors who all specialise in different areas and do the thing most of them suggest.
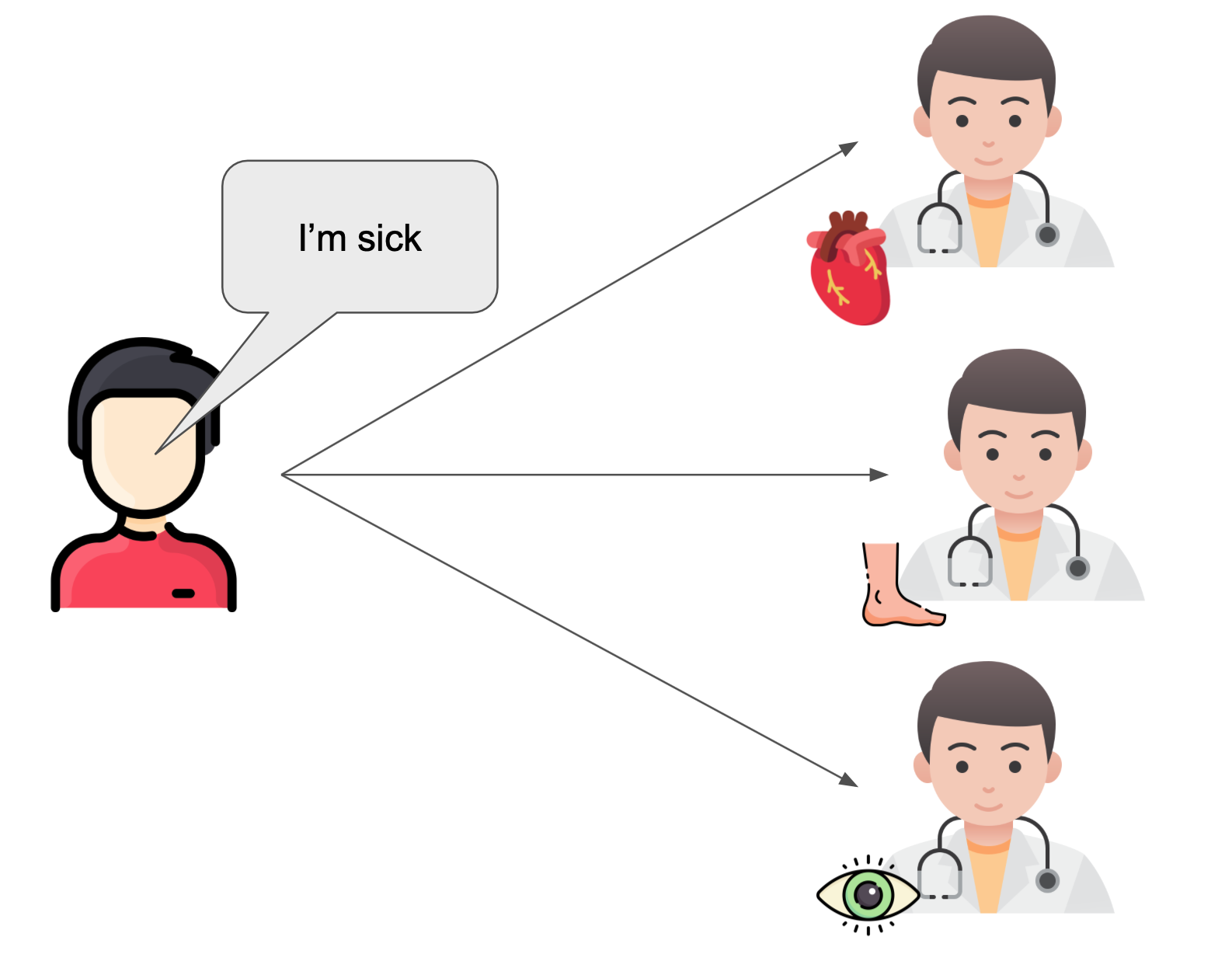
This is much better. If you have a problem with your eyes, you know that the eye doctor is being consulted so you have a much better chance of getting the right treatment. But there are downsides here. Most notably, asking multiple doctors is probably pretty inefficient. Now we have to see 50 specialists for every problem even though most of them have no idea about our problem. What we would prefer is to know which one specialist (or possibly couple of specialists) we should see and only get advice from them.
Approach 4: Go to your GP, tell them about your ailment and ask them which doctor you should go and see.

Here we get the benefits of getting advice from the most relevant specialised doctor without having to ask every other doctor. This is both more accurate and time-efficient.
In approach 4, the GP is the routing function. They know the strengths of the different doctors and send you to one of them depending on your problem.
The Doctors are the Experts. We allow them to specialise knowing that the GP can route us to the correct doctor for our problem.
The GP-doctor system is exactly a Mixture of Experts layer.
What Are MoEs Good For?
Viewed this way we see that Mixture of Expert models will be effective whenever we want a model to have access to large amounts of information - more than a single Expert could hope to learn alone. Another use case is when our task can be decomposed into one of a number of tasks.
In general we might imagine MoEs which when faced with more difficult problems can send the input to a more powerful expert which has access to more resources. This starts to move us increasingly towards Adaptive Computation.
-
This phenomena is known as negative interference in learning. Jack of All Trades, Master of None. For other tasks we can see positive interference however, also known as Transfer Learning. ↩
-
For some vague definitions of “intelligence” and “knowledge”. This intuition is courtesy of Noam Shazeer. ↩
-
In reality both knowledge and cognitive ability are hard to separate this cleanly but hopefully the intuition still remains useful. ↩
-
The experts “compete” to process the tokens and as in Natural Selection and Economics, competition for niches makes them specialise. ↩
-
In actuality Expert might not necessarily specialise strictly by task. It might be beneficial for an expert to specialise in syntactic rather than semantic features or to combine two tasks which are different enough to not inference with each other. ↩
-
This approach also has good biological precedent. Humans don’t use every part of their brain for every stimulus they receive - when they receive, for example a visual stimuli, they use only their visual cortex to process it. ↩
-
In the statistical sense ↩
If you'd like to cite this article, please use:
@misc{kayonrinde2023moe-analogy,
author = "Kola Ayonrinde",
title = "An Analogy for Understanding Mixture of Expert Models",
year = 2023,
howpublished = "Blog post",
url = "http://www.kolaayonrinde.com/2023/10/22/moe-analogy.html"
}